Last update: 20180828
什么是TimeSeries关联性分析(Correlation Analysis)
假设有基于时间序列采集的两组同样大小的数据,关联性分析是指量化这两组数据间的关联程度。再次强调一下,本文中讨论的关联性分析是针对TimeSeries数据类型的,在自然语言处理中用到的关联性分析方法是基于信息熵,与文本中讨论的方法不相同,虽然他们都属于关联性分析。
- 如果数据A上涨时,数据B上涨(同样适应于下跌的情况)则说明这两组数据有关联性,表示为正向关联。
- 如果数据A上涨时,数据B下跌则说明这两组数据有关联性,表示为反向关联。
- 关联程度取决于两组数据间的变化幅度。
为什么要做关联性分析
包括但不限于:
- 使用聚类算法定位性能瓶颈。
- 结合数据可视化,进行信息挖掘。
- 根因分析。
实践中比较实用的用法是分析某个指标的变动会引起哪类其他指标的变动。比如可以回答如下问题:
- Memory Cached与Memory Free间是什么关系?关联程度如何?
- IO WriteBack频繁程度与哪种指标有关联?
在设计系统资源调度策略与参数配置上,这类信息有助于系统最优设计。当优化某个关键指标时,需要查看与其关联的其他指标以确保不会出现指标失衡情况(改善一个指标时导致另一个指标的恶化)。通过此方法还可以分析出设备的硬件配置在运行用户负载程序时它的主要瓶颈是什么,针对不同资源瓶颈,配置不同的资源调度参数以实现能效的最优化。
常用算法之 - Pearson Correlation Coefficient
公式 - 来自Wikipedia
- Python Code: Scipy.stats.pearson()
- 取值范围: [-1.0 ~ 1.0]
使用Pearson时的注意点如下:
- 函数结果的绝对值越接近1.0则关联性越强,越趋近于0.0则表明没有关联性。
- 两组数据间需要有独立性。
- 样本间需要有线性关系。
常用算法之 - Spearman Rank Correlation Coefficient
公式 - 来自Wikipedia
- Python Code: Scipy.stats.spearmanr()
- 取值范围: [-1.0 ~ 1.0]
使用Spearman时的注意点如下:
- 函数结果的绝对值越接近1.0则关联性越强,越趋近于0.0则表明没有关联性。
- 两组数据间需要有独立性。
- 样本间不止线性关系,满足单调关系时也适用。
不过从实际表现来看,Pearson与Spearman不需要严格的遵从关系函数(线性,单调)。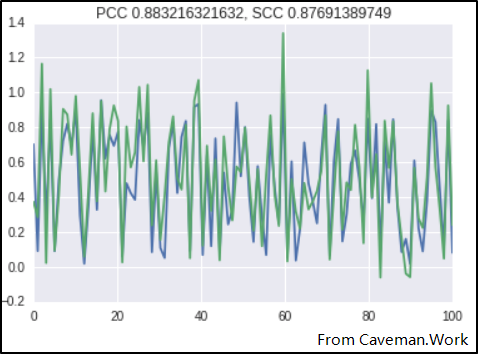
常用算法之 - Normalized Cross-Correlation
公式 - 来自Anomaly.io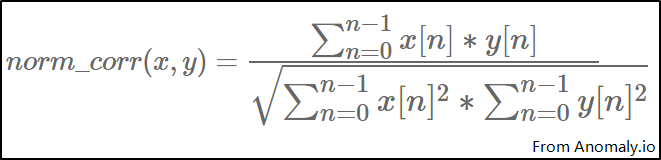
- 函数结果的绝对值越接近1.0则关联性越强,越趋近于0.0则表明没有关联性。
- 抗异常值的干扰能力较强,这也意味着肉眼上看不是很明显的关联关系使用NCC计算时得分是比较高的。
- NCC适合量化两组数据间的数值上的浮动程度(波动)。
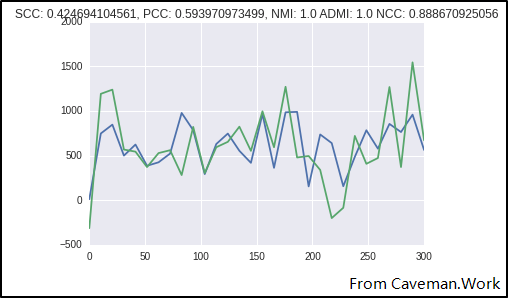
从PCC与SCC的结果上看两组数据没有明显的关联性,但从NCC上看是有较强关系的。从肉眼上分析,两组数据间有较强的”贴合”关系,但不具备明显的关联性关系。
两种关系
将不同指标间的关联性属性划分为:
- 直接关系(Direct Correlation)
- 间接关系(Indirect Correlation)
直接关系是指两个metric间有正向关联或反向关联,总之是有某种的直接关联。间接关系是指两个metric间通过某种逻辑关系关联在一起且数值的变化可能不是实时的,会有一段时间的延迟。需要特殊说明的是,严格意义上来说在一个系统中的任意两个指标都会有关联关系,区别在于关联关系强弱与时效性。
案例分析
Memory Free与Memory Cached间的对比
- NCC较高但Pearson与Spearman给出的低分来看,这两个指标在这段时间内属于间接关联。
- 从free与cached回收原理上看,两个虽然有关系但并不是直接关系。这个依赖具体的PageCache 与Memory Reclaim算法。
Memory Buffers与Memory Cached间的对比
- Pearson与Spearman都给出0.5以上的分,说明两者有一些直接关系,只是强度不是很大。
- 从buffers与cached回收原理上看,两者其实都算是PageCache缓存。当遇到内存吃紧,IO 回写情景时两个buffer都会受到影响。
Memory Free与 UX FrameDrop间的对比
- Pearson与Spearman给出的分数来看,两个指标属于间接关系。
- 从原理上看低内存有可能会引起前台UX应用的卡顿,但这两者间并不具备直接关系。
这里只给出了某个设备在某个时段的信息,而且还只是某个特定UX应用的关联性分析。在实际中,不同UX应用针对不同的metric间的关联性是不同的。比如有些应用是Memory sensitive,而有些是IO sensitive。只有经过大量数据(不同时段)的计算后才能给出较为准确的结论。
其他常见的关联性分析算法,根据特性适用于不同领域。
- Apriori/FP Growth(Tree): 经典的超市关联分析中用到的算法。在多个异常指标的聚类时,也可以用此算法做初步筛查。
- Canonical Correlation Analysis
- Maximum Information Coeffcient
- Kendall Correlation Coefficient
- Euclidean distance
- Mutual Information
写在最后
- 这个世界很复杂,无法用一个指标或者量化方法理解所有现象。
- 使用指标时应根据现实数据情况采用不同的量化指标。
- 先采用数据可视化的方式观察下数据间的大致关系,之后根据其结果选择合适的量化指标。
- 数据可视化工具中可以同时展示关联性指标的计算结果,有助于数据解读。